Building Okayar (Part 2): Infrastructure through Serverless and Terraform

Welcome back!! Long time no talk. For those of you who are new to Okayar, in this series I am going through the steps that I took to build a web application to track my Personal OKRs. You can find more background at my first post along with my back-end setup here!
In Part 2 of this series today, I will be covering my infrastructure setup for Okayar.
Quick aside: What is “Infrastructure” and what is “Infrastructure as Code”?
Infrastructure
Unfortunately, putting anything on the internet (usually) isn’t free. Every line of code you write needs a place to run, i.e. a real life machine somewhere that runs it. Every time a user clicks a button on your website asking for or submitting new information, some machine somewhere has to be ready to “hear” that request. And whenever you collect information from users with the intent to store it, there needs to be a machine somewhere that is physically holding onto that information. That, in a nutshell, is infrastructure. The act of defining which machines and where are handling all the things you want your application to do.
The nice thing about infrastructure in 2021 (or 2020, when I made Okayar) is that you barely have to think about this! Back in the old days if I wanted to build a startup, I’d have to buy my own server rack (a bunch of computers), sit it physically in the office or my home, and configure every single thing about the way those servers worked. What a nightmare. Cloud service providers (AWS being the biggest one and the one I used) have completely changed the game. You hit one button and suddenly you have a database running in some random server room in Oregon. You hit another and now you have a globally-accessible endpoint for users to send to you or request from you information. Life is great.
Infrastructure as Code
Cloud service providers like AWS provide a pretty detailed and easy to use UI console to deploy and manage your infrastructure. Unfortunately, life is not so great when you use this to create all of your infrastructure. Imagine trying to remember exactly which settings you started your server with 4 months after the fact. Or working on a team, and trying to make sure something you change doesn’t affect everyone else’s work. Or coming to work one day and finding out that your teammates broke your server by accident while messing around on the console. All of this misfortune (and more!) is possible when you use the console to configure your infrastructure.
Enter “Infrastructure as Code”. The invention of this was inevitable; I don’t know the history behind it, but teams were probably building this in-house across the tech industry as soon as cloud providers became available. It gives you a way to declaratively write code that defines exactly what your infrastructure that you deploy looks like. And for a lot of reasons, Terraform is my favorite one. This is how insanely easy it is to create a VPC, for example (taken from Terraform website):
The benefits are almost endless; here are the top ones:
- Version-controlled history of your infrastructure. You can see exactly who made which change to your infrastructure setup across your entire account. And, you can make sure that you are not overwriting someone’s work when you are writing your code.
- The ability to generate a “plan”. By inspecting your code and comparing it with the state of the resources that terraform finds in the cloud service, it is able to generate a “plan”, which is a list of proposed changes that your code is making. This is incredibly helpful, so you can verify that what’s in the “plan” is exactly what you are trying to do, and nothing more, nothing less.
- Having a “plan” can be used to create and manage an approvals pipeline. Especially in a big team, you don’t want people making freestyle infrastructure changes. That’d be a calamity just waiting to happen. With Terraform, you can put your “plan” in a pull request and set up approvals just like a regular PR for a code repo. Both your code itself and the “plan” can be verified before deploying your changes.
- Variables that make sense. It’s very common in infrastructure for one resource to rely on another. When setting up an API, for example, you will need to provide the SSL certificate. Terraform makes this easy — in the code for the API, I can simply reference
aws_acm_certificate.my_certificate.arn. Now, my API knows exactly which certificate to use. Elegant and simple. - You get to use modules. Basically, you can import entire blocks of resources that someone else wrote. These are managed by the community and there’s one for almost anything. This way, you just pass in your configuration as variables, and get to utilize someone else’s code to spin up all the resources you need.
I could go on and on, the conclusion I’m trying to get to is that “Infrastructure as Code” is incredible. I can write 4 lines of code, type “terraform apply”, and spin up a server in AWS in under a minute. It’s never been easier to join the software world :)
Back-end Infrastructure Diagram
The next few sections in this post will be me setting up various back-end services. I’ve put an architecture diagram here so you can follow along!
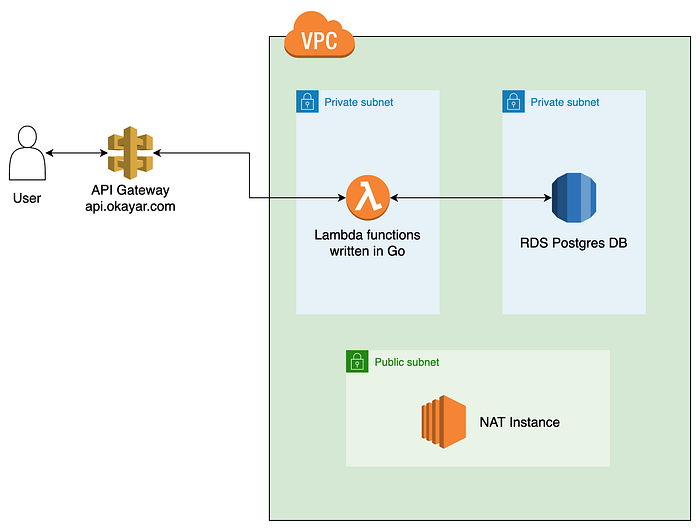
My back-end itself is really, really straightforward! An API Gateway sends traffic to Lambda, which then interacts with my RDS Database. The NAT instance sits in the public subnet and provides internet access to my private subnets. All these decisions will be explained in further sections :)
Setting up the VPC
Now to the actual infrastructure — the first step of setting up Okayar was creating a VPC with private and public subnets. A “subnet” is just a range of configured IPs that services you deploy can use to run. The distinction is pretty simple — a private subnet should not be visible to the greater internet. I would not want to give the general internet the ability to even see my database’s name or host address. A public subnet is where you would put something that should be seen by the internet. For example, if I had a Ruby on Rails server that is serving traffic to my website, I’d want it to be on a public subnet, so that a user on my website would be able to make an API call to it. And, true to terraform fashion, the code for this is very straightforward:
The only slightly complex thing that you run into when deploying a VPC is giving your private subnet a way to communicate with the internet. Now, remember we said that the internet shouldn’t be able to reach your private subnet. Resources in a private subnet, however, still need a way to reach the internet. For example, if you are running a postgres database in a private subnet, this database needs a way to search for updates and keep itself up to date. The typical way to do this is a NAT gateway, which is a fully-managed (read: you don’t have to do anything) service provided by AWS.
For me though, this is just a fun project. And a NAT Gateway starts at $32.40 a month, plus more per GB of data processed. Luckily, there’s another (not recommended for production applications) option: the NAT instance. This is basically just spinning up an EC2 with minimal cost that serves the same purpose, but with less reliability than AWS’s fully managed service. The module I used for this can be found here! And the code snippet, as always, is simple as ever:
And there it is! A VPC set up for use. Now we have a home for all our resources.
Creating the Database
The next step in setting up the infrastructure was creating a database to store all our information. Any time a user creates an objective, or creates a key result, or creates an account — we need to be able to store their information and retrieve it when necessary. My options here were to use a RDBMS (Relational DB) like Postgres, or a NoSQL like DynamoDB.
Using a DynamoDB, especially for a small application like this, is very tempting! Most of all, it’s easy. For those who aren’t familiar, there’s no real infrastructure to set up; you just hit “Create Table” and you’re ready to go, with any “columns” (NoSQL geeks will get the quotes) you need being automatically created when you create any given row. Even accessing/editing the live data is incredibly easy via the DynamoDB UI. Inherently, DynamoDB fits into the “serverless” way of thinking — since it is managed by AWS, there is near endless scaling as an application grows and there are no servers for me as a developer to manage. There are “read and write units” that I have to configure, but these are seamlessly autoscaled. I didn’t use DynamoDB though, (a) because my data is relational in its nature, so DynamoDB would be the easy way out and (b) because I wanted to learn how to use GORM in Golang with a traditional database, which I covered in Part 1 of this series.
So, once I chose creating a Postgres database, I still had a couple options. My preferred option was to use the Amazon Aurora Serverless database. This is a fully managed (Postgres or MySQL) database provided by AWS that has the typical fully managed benefits. Specifically to serverless, its benefit is autoscaling based on traffic at any point. It can very easily scale from 1 user to 1000 users as needed, which is a huge benefit to building a serverless application. It also has the typical fully-managed benefits — higher performance, near-bulletproof availability, and way easier to configure than directly configuring a Postgres DB.
Unfortunately, I once again ran into small-project-pricing issues. The smallest units of scalability that the database can run at is 2 ACUs (Aurora Capacity Units). You can keep it at 0 units, but the startup time when making a request to it is too much to deal with — nobody wants to wait 20 seconds the first time they make a request just because the DB hasn’t started up yet. The cost to keep a database running at 2 ACUs though, is a little more than $86/month. Which for a side project, I didn’t really feel like paying.
So, I settled for a good ol’ regular Postgres RDS. One thing to note is that you have to use a t2.small, because a t2.micro is not able to encrypt its data. And for a user-facing app, encryption is a must. The code for this, as always, is criminally easy:
Setting up the API via Serverless…and Terraform
Serverless
As I mentioned in Part 1, one new thing I did while building Okayar is use the Serverless framework. And, as I mentioned, I was very unsettled by having my application code repo also dictate my infrastructure. What I mean by this, is that usually in software development my “infrastructure” is separate from my “code”. For example, if I am building a Ruby on Rails app, my application logic will be in the Rails repo. Separately, I’ll have my Terraform/Cloudformation repo that defines my ECS setup for that Rails server. In Serverless, it’s kind of a 2-in-1. My application code lives across the repo, and then I define my infrastructure for the entire back-end in a file called serverless.yml. This infrastructure comes in the form of an API Gateway and some supporting features.
API Gateway is again a fully-managed AWS service that makes our lives easier. Basically, I am able to define routes and methods that I want to make available to the world, and API Gateway does so. Not only that, but it uses Cloudfront to distribute this API Gateway, so my endpoints are automatically highly available around the world. This is a huge improvement over the “old way” of deploying APIs, where I’d have to deploy and manage my own servers just to receive requests on the internet. Of course AWS is using servers behind the scenes, but it’s amazing to not have to worry about it!
There’s a ton of documentation on Serverless out there so I won’t dive into every little block, but I will try and highlight some details that were important to Okayar.
First, the provider block:
Here, I just define useful parameters for the functions to run with. I choose their runtime (go1.x because I’m using Go), their assigned memory, region, stage, and so on. The security group is important to define what resources the lambda is allowed to access (needs database access, for example). The VPC block is probably the most important thing here — it is essential that the lambdas be in the VPC and in the private subnets, so they are (a) able to talk to the required resources in AWS and (b) not accessible from outside of my AWS setup. Lastly, I can tell Lambda where to go look for my secrets (passwords) in AWS.
Next is the functions block, which I just really like for how clean it is:
This section creates the API gateway methods that I desire, and links them to the code that I have written in this repo. Put simply, this is the bridge between API Gateway (which is available to the world) and my lambda (which users can only reach through API Gateway). One thing to note here is that I send every REST method for a given endpoint (objectives or key_result) to the same function handler. So, no matter what method /objectives is hit with, it gets routed to bin/objectives. The mechanics of how I handle these different methods are also covered in Part 1 of this blog!
Lastly, there are the plugins & custom blocks. These enable various features I want my API gateway to have.
- serverless-domain-manager: This is incredibly important to have a real domain for the API to be available at (for me, this is api.okayar.com). Otherwise, API Gateway by default deploys an api with a random XYZ.cloudfront.net address. Obviously, this is not ideal. We want a real domain for a front-end to be able to talk to. Within the custom section, I specify the domain I want and tell the plugin to create a Route 53 entry. This creates my custom domain!
- serverless-offline: This is essential for local development! Those of you familiar with servers will be familiar with spinning up a local instance of your server to test against. Well….with serverless….there’s not really a server to spin up. Hence, serverless-offline. It’s basically doing what we need (and creating a server we don’t have to think about) that will provide local versions of the endpoints I need. Extremely important for speedy back-end development and also for front-end development to have a scratch env to test against.
- serverless-dotenv-plugin: Most developers will be familiar with “dotenv”. This is how we define environment variables across local dev, staging, and production. This is therefore essential to writing clean, testable, and easy-to-develop code!
- serverless-api-gateway-throttling: This is a layer of protection you can add to your API Gateway so that user(s) cannot spam your endpoints.
- serverless-associate-waf: Links a WAF (Web Access Firewall) to the API Gateway for security features.
Terraform
As hinted at in the title for this section, we do have some Terraform involved here. One, I created the ACM Cert for api.okayar.com. I will cover the ACM cert creation above for app.okayar.com, so I’ll leave it out here. Second, I created the Web Access Firewall (WAF) for the API Gateway. This has a couple important security features that enable protection from things like DDOS from bad actors. I’m going to keep it hidden to protect myself…but I would recommend this for any internet facing app. It starts at like $5/month and is probably worth the cost.
Hosting the Front-End
In a later segment in this series, we will cover the front-end built in React. Assuming this already exists, we need a way to serve this content to a user who visits app.okayar.com. Luckily, we have a module that’s perfect for the occasion. It creates:
- An S3 bucket to hold the content
- A Cloudfront distribution that will serve the content from S3 from multiple nodes around the world
- A Route 53 record that tells the world that app.okayar.com maps to the Cloudfront distribution
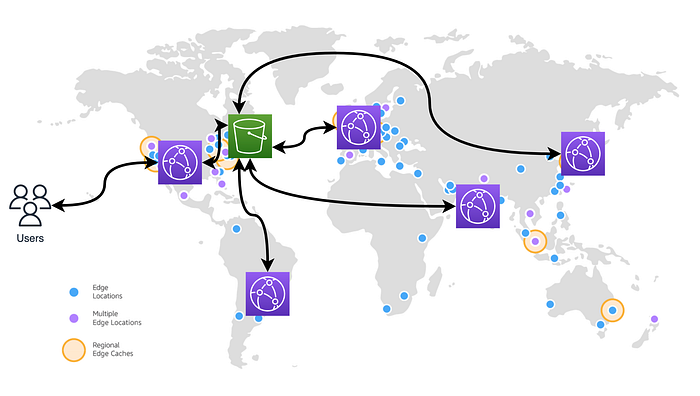
Some background on Cloudfront — it’s a global content delivery network that works, in my opinion, really, really well. It’s highly available like every other AWS service, and works super well in serving static websites via S3. It maintains a cache (or doesn’t if you don’t want it to) of the S3 content. It handles SSL termination at its edge, which is very helpful for a web app like this. And lastly (off the top of my head), it allows you to set up redirect paths for errors, which is essential for a React app. Might there be better CDNs out there? Probably. But within the AWS ecosystem, it serves its purpose well.
Here is the code that I used from the module:
And outside of the module, I created an ACM certificate for the UI that is DNS-validated (not worth diving into):
The result of all this is a Cloudfront distribution that is able to serve my content globally. No matter where a user is in the world, they should be able to access my website at app.okayar.com!
Conclusion
I hope those of you interested in developing web apps found this helpful! Infrastructure isn’t the most fun to talk about, but it’s essential and feels great when you get it working. My personal conclusion is that Terraform is awesome and everyone should use it for their infrastructure :)
Please let me know if I missed anything! And stay tuned for the following blog posts in this series:
- UI, built using React
- Auth, handled via Firebase Auth, and integrated with both my back-end and front-end
Thanks and see you soon!
